Step-wise Disambiguation
When resolving ambiguities in natural language queries, we employ a step-wise reasoning approach that mimics human decision-making processes. This approach involves:
- Data Selection Reasoning: Identifying relevant data columns and filters from the query
- Chart Type Reasoning: Determining appropriate visualization types based on analytical tasks
- Channel Mapping Reasoning: Assigning data elements to visual channels
- Data Transformation Reasoning: Specifying operations like aggregation or filtering
- Visualization Synthesis: Generating complete visualizations that represent valid interpretations
This structured approach enables systematic resolution of ambiguities while preserving multiple valid interpretations of the original query.
Ambiguity-Injected NL2VIS Data Synthesizer
We developed a data synthesizer that systematically introduces ambiguity into seed visualizations. This approach ensures control over the types of ambiguity while maintaining meaningful, interpretable outputs.
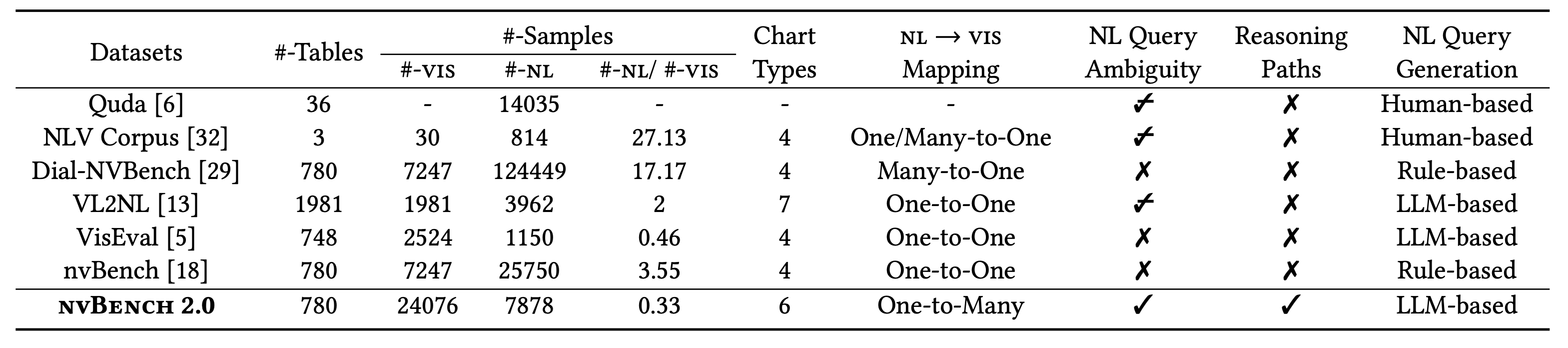
Benchmark Comparison
nvBench 2.0 introduces several key innovations compared to existing NL2VIS benchmarks, particularly its explicit handling of query ambiguity and support for one-to-many mapping between queries and visualizations.
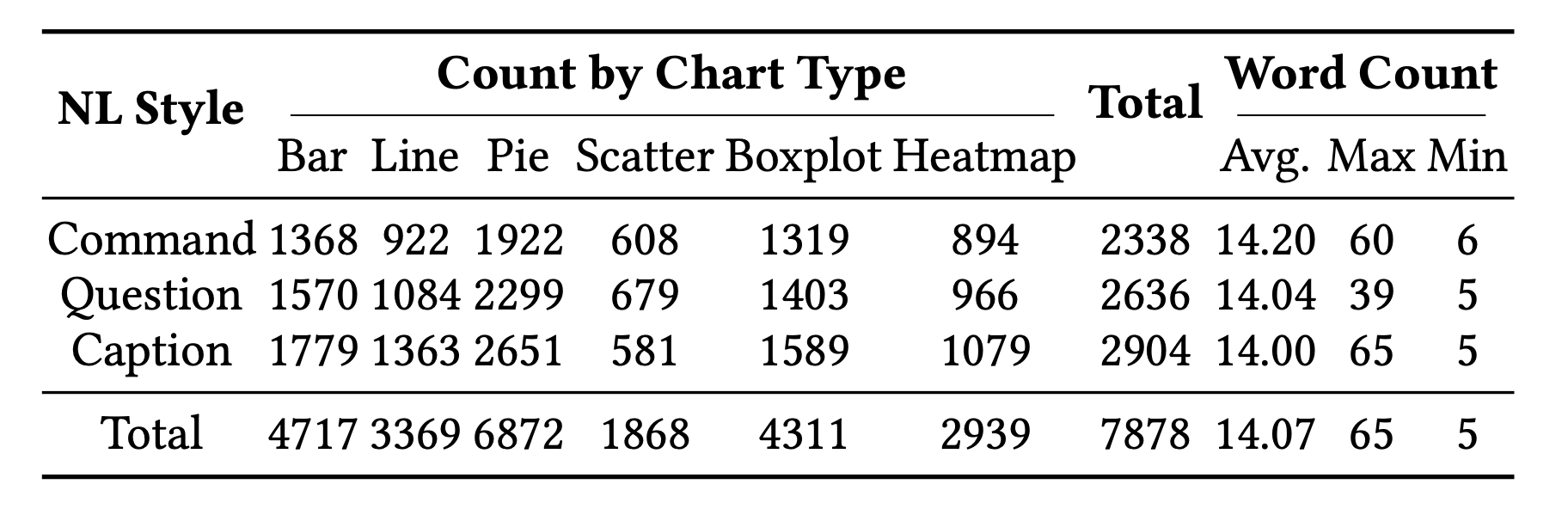
Benchmark Statistics
nvBench 2.0 includes a diverse range of natural language query styles and chart types, ensuring comprehensive coverage for evaluating NL2VIS systems.
nvBench 2.0 includes detailed statistics on ambiguity types and patterns, providing insights into the distribution and frequency of different ambiguity categories.
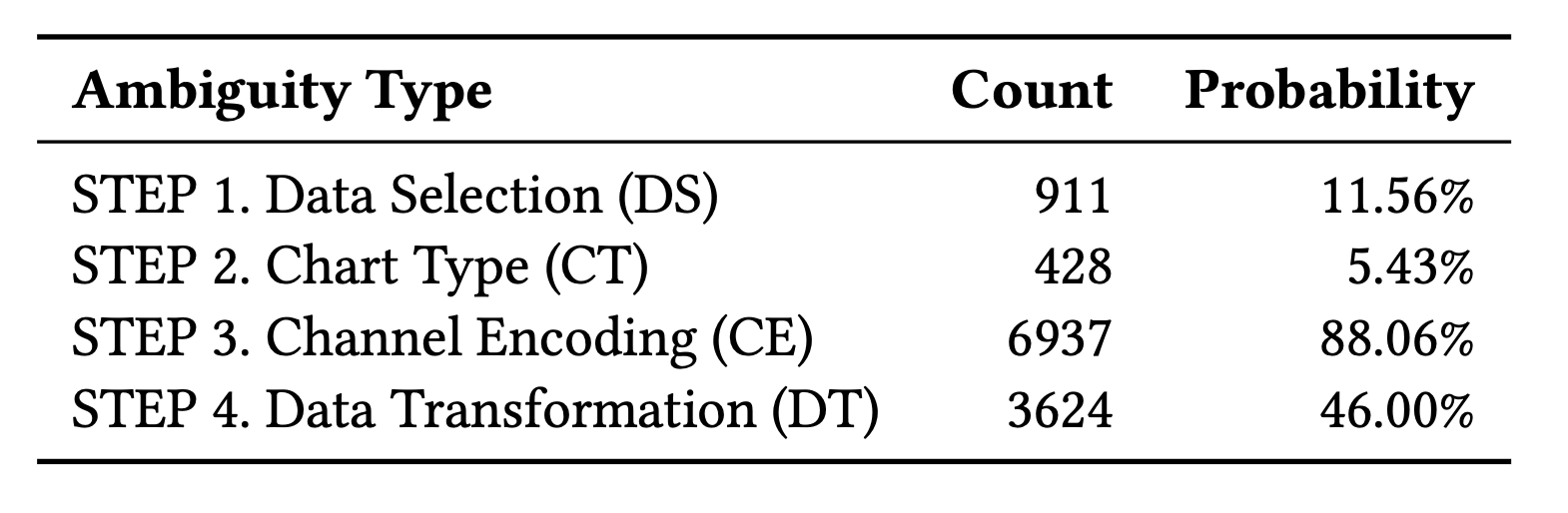
Table 4: Ambiguity count at each reasoning step.
This table shows the distribution of ambiguities across different reasoning steps in the nvBench 2.0 dataset, highlighting which steps in the visualization process are most prone to ambiguity.
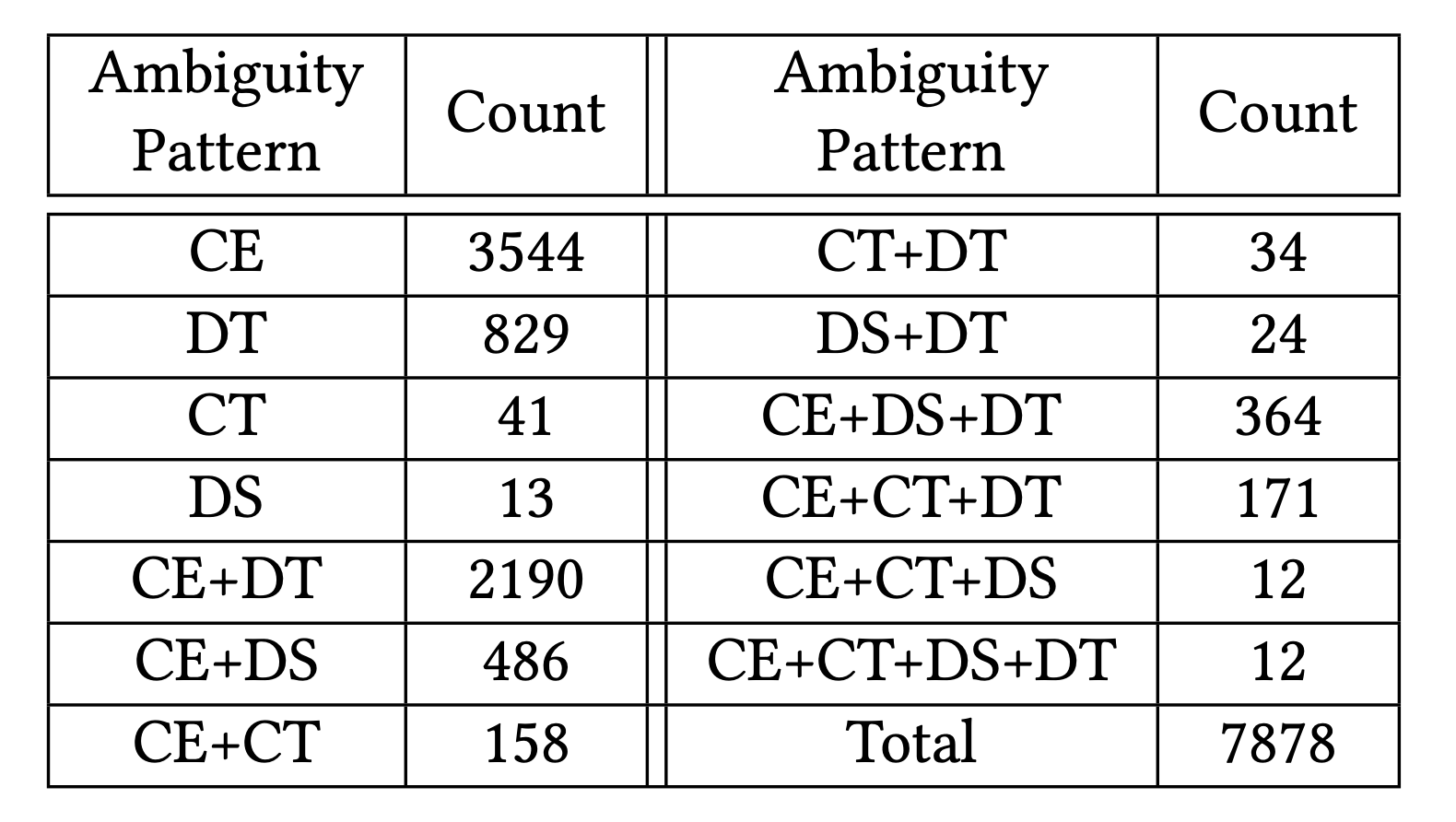
Table 5: Statistics of ambiguity patterns.
Our dataset contains diverse ambiguity patterns, with Channel Encoding (CE) being the most common type of ambiguity (88.06%), followed by Data Transformation (DT) ambiguities (46.00%). Many samples contain multiple types of ambiguity, highlighting the complexity of real-world visualization requests.
Step-NL2VIS for Ambiguous NL2VIS
We propose Step-NL2VIS, an LLM-based model trained on nvBench 2.0, which addresses ambiguity by incorporating a step-wise reasoning process and leveraging preference optimization.
Preference Optimization with Step-DPO
Step-DPO utilizes step-wise paired correct and incorrect samples for preference optimization, delivering rich process supervision signals to the model and fostering improved accuracy at each step.
Where Dp represents a step-wise preference dataset, πθ(·|x, s1~k-1) denotes the policy model to be optimized, πref(·|x, s1~k-1) refers to the reference model, and β controls the divergence between the optimized policy and the reference model.
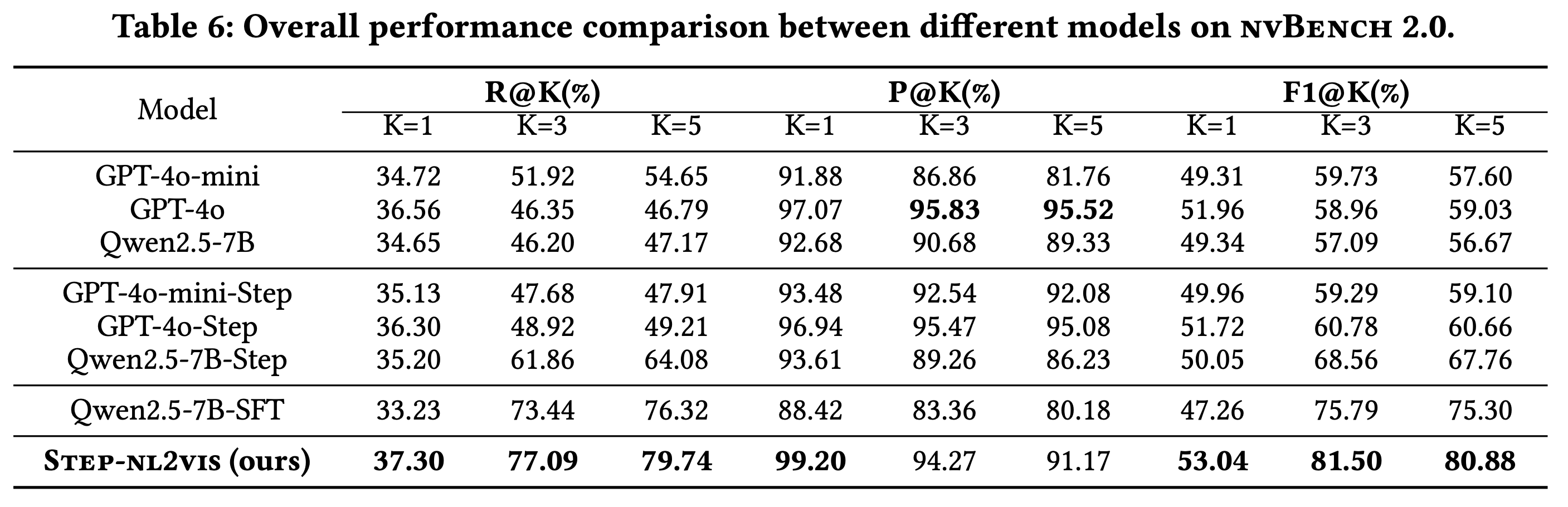
Experiments
We evaluate the performance of various models on the ambiguous NL2VIS task using nvBench 2.0, comparing our Step-NL2VIS model against state-of-the-art approaches.
Overall Performance
The table below presents the comprehensive performance evaluation of different models on nvBench 2.0. Our proposed Step-NL2VIS achieves state-of-the-art performance across most metrics.
Citation
If you find nvBench 2.0 useful for your work, please cite:
@misc{luo2025nvbench20resolvingambiguity,
title={nvBench 2.0: Resolving Ambiguity in Text-to-Visualization through Stepwise Reasoning},
author={Tianqi Luo and Chuhan Huang and Leixian Shen and Boyan Li and Shuyu Shen and Wei Zeng and Nan Tang and Yuyu Luo},
year={2025},
eprint={2503.12880},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2503.12880},
}
License